To deploy a new VPC and all of it’s resources (Subnets, Routes, IGWs, NAT Gateways, Peers).
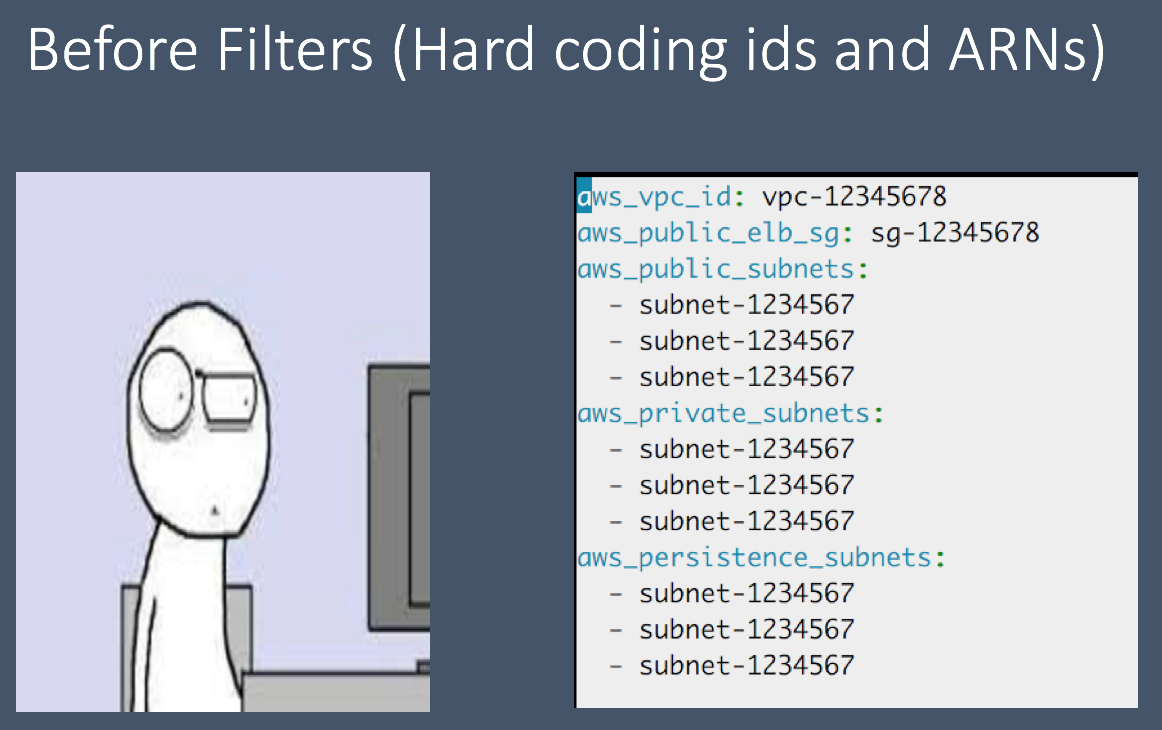
Example of hard coding IDs in group_vars. “group_vars/environments/test/network.yml“
Now you still have to deploy the AWS resources your services depend on (RDS, Security Groups, ELB, ASG, Kinesis, SQS, etc…).
*Example of not using filters in a role “roles/services/vars/webapp.yml*”

Now if I had to do that for every VPC we manage, I would lose my mind. Also what if I want to deploy a new VPC to test out a new feature. This is not only time consuming but a real pain in the ass. Would you not rather come up with a name scheme for your AWS infrastructure and based on that name scheme. Now you will no longer have to worry about hard coding IDs or ARNs any more.
I see Ansible filters as easy to write Python functions. Anything you can write in a function can be used as a filter. If you have been writing scripts in Python for a while, you will find that writing Ansible plugins is such a breeze.
Due to the awesomeness of filters, I no longer have to hard code any ARN or ID in any of my playbooks. Instead I have a filter that grabs the ARN for me based on the name of the resource.
In order for these AWS filters to work, you will need to use the Name tag for all of your services.
My decision to use the filter plugin instead of the lookup plugin, is purely a choice based on taste. I do not want to have a Python file for each lookup that I require. I rather write a module for each type of filtering that I need to do. For instance, my aws calls are in the filter_plugins/aws.py.
The get_rds_endpoint filter will query the AWS API using the RDS instance name and return back the endpoint address.
The get_rds_endpoint function is 15 lines of code and 13 lines of documentation. Such a small script and yet it has saved me from hard coding.
---
aws_region: us-west-2
mysql_server: "{{ aws_region | get_rds_endpoint(rds_instance_name) }}"
memcached_server: "{{ aws_region | get_elasticache_endpoint(memcached_instance_name) }}"
redshift_server: "{{ aws_region | get_redshift_endpoint(redshift_name) }}"AnsibleFest2016-Deploying-To-AWS
Deploying to AWS using Ansible and Magic